Mapping the IRS Form 990 Data Repository - A Computational Approach to Nonprofit Data Discovery
Introduction
The Internal Revenue Service (IRS) Form 990 is a mandatory annual filing for tax-exempt organizations in the United States, providing critical data on financial performance, governance, and operational activities. Researchers, data analysts, and nonprofit sector stakeholders frequently seek access to this data to calculate performance metrics, evaluate organizational effectiveness, and conduct comparative analyses. However, programmatically accessing this data remains challenging due to the complex repository structure maintained by the IRS.1
Efficiently accessing Form 990 data requires understanding how the IRS organizes their data repository, including the hierarchical structure of index files and the pathways to actual XML filings. While the IRS provides public access to Form 990 data through their website, the repository’s scale and organization create substantial barriers to targeted retrieval, especially when seeking specific organizations by Employer Identification Number (EIN). Third-party platforms like ProPublica’s Nonprofit Explorer have attempted to address this challenge by providing more accessible APIs, but these solutions often lack the comprehensive coverage of the primary IRS repository.2
Prior work on nonprofit financial data extraction has typically relied on such third-party sources, which frequently contain only a subset of the available data, with limited timeframes and fields.3 Our previous research demonstrated the challenges of retrieving Program Efficiency (PE) and Fundraising Efficiency (FE) metrics through ProPublica’s API, with consistent gaps in data availability affecting comprehensive analysis. These limitations motivate a direct approach to the primary IRS data repository, requiring a thorough understanding of its organization and structure.
The aim of this study is to develop a computational methodology for mapping the IRS Form 990 data repository structure to enable more efficient and targeted data retrieval. Specifically, we seek to identify and catalog the repository’s hierarchical organization across available years, understand the relationship between index files and actual XML filings, determine the structure of index files and how they reference individual organizational filings, and create a visual and structured representation of the repository to inform targeted data retrieval.
By systematically mapping the repository structure, we provide a foundation for more efficient data retrieval strategies that avoid unnecessary downloads while ensuring comprehensive coverage. This approach addresses a critical gap in nonprofit data accessibility, potentially enabling more thorough analyses of organizational performance and financial metrics across the sector.
Experimental
pip install requests beautifulsoup4 matplotlib networkx rich#!/usr/bin/env python3
"""
IRS Form 990 Repository Structure Mapper
This script maps the structure of the IRS Form 990 data repository without downloading
actual filings. It identifies index files, their organization, and creates a visualization
of the repository structure.
The goal is to understand:
1. How the repository is organized
2. What index files are available
3. How these index files are structured
4. How to locate specific filings in later phases
"""
import requests
import logging
import json
import re
import csv
import io
import zipfile
from pathlib import Path
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import time
from rich.console import Console
from rich.table import Table
from rich.progress import Progress
import matplotlib.pyplot as plt
import networkx as nx
from textwrap import wrap
# Setup logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("irs_structure_mapper.log"),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
# Rich console for pretty output
console = Console()
# Constants
IRS_DOWNLOADS_PAGE = "https://www.irs.gov/charities-non-profits/form-990-series-downloads"
AWS_BASE_URL = "https://apps.irs.gov/pub/epostcard/990"
MAPPER_DIR = Path("irs_mapping")
MAPPER_DIR.mkdir(exist_ok=True)
# Create directories for different data
INDEX_INFO_DIR = MAPPER_DIR / "index_info"
INDEX_INFO_DIR.mkdir(exist_ok=True)
VISUALIZATION_DIR = MAPPER_DIR / "visualizations"
VISUALIZATION_DIR.mkdir(exist_ok=True)
# Target EINs for reference
TARGET_EINS = {
"13-6213516": "American Civil Liberties Union Foundation",
"53-0196605": "American National Red Cross",
"13-1635294": "United Way Worldwide",
"13-1644147": "Planned Parenthood Federation of America",
"53-0242652": "Nature Conservancy"
}
def respect_rate_limit(last_request_time, rate_limit=0.5):
"""Ensure we don't exceed the rate limit."""
elapsed = time.time() - last_request_time
if elapsed < rate_limit:
time.sleep(rate_limit - elapsed)
return time.time()
def explore_downloads_page():
"""
Analyze the downloads page to find index files and understand their organization.
Returns:
Dictionary containing the repository structure information
"""
console.print("[bold blue]Analyzing IRS Form 990 downloads page...[/bold blue]")
try:
response = requests.get(IRS_DOWNLOADS_PAGE)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# Extract all links
links = []
for a_tag in soup.find_all("a", href=True):
href = a_tag["href"]
text = a_tag.get_text(strip=True)
# Make URL absolute if it's relative
if not href.startswith("http"):
href = urljoin(IRS_DOWNLOADS_PAGE, href)
links.append({
"url": href,
"text": text
})
# Identify index files (CSVs and ZIPs)
index_files = []
years_found = set()
for link in links:
# Look for links that appear to be index files for Form 990
url = link["url"]
if ("990" in url and (".csv" in url.lower() or ".zip" in url.lower())):
# Try to extract the year
year_match = re.search(r'20\d{2}', url)
year = year_match.group(0) if year_match else "unknown"
years_found.add(year)
index_files.append({
"url": url,
"text": link["text"],
"year": year,
"file_type": "csv" if ".csv" in url.lower() else "zip"
})
# Organize findings by year
years_data = {}
for year in years_found:
if year != "unknown":
years_data[year] = {
"index_files": [f for f in index_files if f["year"] == year]
}
# Create repository map
repository_map = {
"download_page": IRS_DOWNLOADS_PAGE,
"aws_base": AWS_BASE_URL,
"index_files": index_files,
"years": years_data,
"years_count": len(years_found),
"index_files_count": len(index_files)
}
# Save the repository map
output_path = MAPPER_DIR / "repository_map.json"
with open(output_path, "w") as f:
json.dump(repository_map, f, indent=2)
console.print(f"[green]Found [bold]{len(index_files)}[/bold] potential index files across [bold]{len(years_found)}[/bold] years[/green]")
console.print(f"[green]Repository map saved to [italic]{output_path}[/italic][/green]")
return repository_map
except requests.RequestException as e:
logger.error(f"Failed to analyze downloads page: {e}")
console.print(f"[bold red]Error analyzing downloads page: {e}[/bold red]")
return None
def sample_index_file_structure(url, file_type, year):
"""
Sample the structure of an index file without downloading it entirely.
For CSV files, read just the headers and a few rows.
For ZIP files, just examine the file list.
Args:
url: URL of the index file
file_type: Type of file ('csv' or 'zip')
year: Year associated with the file
Returns:
Dictionary with information about the file structure
"""
last_request_time = time.time()
try:
info = {
"url": url,
"file_type": file_type,
"year": year,
"structure_analyzed": False
}
if file_type == "csv":
# For CSV, request just enough to get headers and a few rows
headers = {"Range": "bytes=0-8192"} # First 8KB should be enough for headers and a few rows
last_request_time = respect_rate_limit(last_request_time)
response = requests.get(url, headers=headers)
if response.status_code in (200, 206):
# Try to parse as CSV
text_content = response.text
csv_reader = csv.reader(text_content.splitlines())
rows = list(csv_reader)
if rows:
headers = rows[0]
info["column_headers"] = headers
info["sample_rows_count"] = min(5, len(rows) - 1)
info["sample_rows"] = rows[1:info["sample_rows_count"]+1] if len(rows) > 1 else []
info["structure_analyzed"] = True
# Check for EIN column
ein_column_index = None
for idx, header in enumerate(headers):
if "ein" in header.lower():
ein_column_index = idx
info["ein_column_index"] = idx
info["ein_column_name"] = header
break
# Check for OBJECT_ID or similar that might point to file locations
object_id_column_index = None
for idx, header in enumerate(headers):
if any(id_term in header.lower() for id_term in ["object", "id", "file", "location", "url"]):
object_id_column_index = idx
info["object_id_column_index"] = idx
info["object_id_column_name"] = header
break
elif file_type == "zip":
# For ZIP, we'll just check if it's accessible, without downloading the whole thing
headers = {"Range": "bytes=0-64"} # Just get the file signature
last_request_time = respect_rate_limit(last_request_time)
response = requests.get(url, headers=headers)
if response.status_code in (200, 206):
info["is_accessible"] = True
info["content_type"] = response.headers.get("Content-Type")
info["structure_analyzed"] = True
# Try to get the full file size
if "Content-Range" in response.headers:
range_info = response.headers["Content-Range"]
match = re.search(r"bytes 0-\d+/(\d+)", range_info)
if match:
info["file_size"] = int(match.group(1))
# We won't try to extract the ZIP contents as that would require downloading
# the whole file, which we're avoiding in this structure mapping phase.
info["note"] = "ZIP file detected, but contents not examined to avoid large download"
# Save the sample information
filename = url.split('/')[-1].replace(".", "_")
sample_path = INDEX_INFO_DIR / f"{year}_{filename}_structure.json"
with open(sample_path, "w") as f:
json.dump(info, f, indent=2)
return info
except Exception as e:
logger.error(f"Failed to sample index file {url}: {e}")
return {"url": url, "error": str(e), "structure_analyzed": False}
def generate_repository_visualization(repository_map):
"""
Generate visualizations of the repository structure.
Args:
repository_map: Dictionary containing repository structure information
"""
console.print("[bold blue]Generating visualizations of repository structure...[/bold blue]")
# 1. Create a bar chart of index files by year
years = sorted(repository_map["years"].keys())
file_counts = [len(repository_map["years"][year]["index_files"]) for year in years]
plt.figure(figsize=(12, 6))
plt.bar(years, file_counts, color='skyblue')
plt.xlabel('Year')
plt.ylabel('Number of Index Files')
plt.title('IRS Form 990 Index Files by Year')
plt.xticks(rotation=45)
plt.tight_layout()
# Save the chart
chart_path = VISUALIZATION_DIR / "index_files_by_year.png"
plt.savefig(chart_path)
plt.close()
console.print(f"[green]Bar chart saved to [italic]{chart_path}[/italic][/green]")
# 2. Create a network graph of the repository structure
G = nx.DiGraph()
# Add root node
G.add_node("IRS Form 990 Repository")
# Add year nodes
for year in years:
G.add_node(f"Year {year}")
G.add_edge("IRS Form 990 Repository", f"Year {year}")
# Add index file nodes
for idx, file_info in enumerate(repository_map["years"][year]["index_files"]):
file_name = file_info["url"].split('/')[-1]
file_type = file_info["file_type"].upper()
node_name = f"{file_name}\n({file_type})"
G.add_node(node_name)
G.add_edge(f"Year {year}", node_name)
# Create the visualization
plt.figure(figsize=(15, 10))
pos = nx.spring_layout(G, k=0.5, iterations=50)
# Draw nodes
nx.draw_networkx_nodes(G, pos,
node_size=2000,
node_color="skyblue",
alpha=0.8,
node_shape="o")
# Draw edges
nx.draw_networkx_edges(G, pos,
edge_color="gray",
arrows=True,
arrowsize=15)
# Draw labels with wrapped text
labels = {node: '\n'.join(wrap(node, 20)) for node in G.nodes()}
nx.draw_networkx_labels(G, pos,
labels=labels,
font_size=8,
font_family="sans-serif")
plt.axis('off')
plt.title("IRS Form 990 Repository Structure")
plt.tight_layout()
# Save the network graph
graph_path = VISUALIZATION_DIR / "repository_structure.png"
plt.savefig(graph_path, dpi=300)
plt.close()
console.print(f"[green]Network graph saved to [italic]{graph_path}[/italic][/green]")
def generate_summary_report(repository_map, sampled_indexes):
"""
Generate a summary report of the repository structure.
Args:
repository_map: Dictionary containing repository structure information
sampled_indexes: List of dictionaries with information about sampled index files
"""
console.print("[bold blue]Generating summary report...[/bold blue]")
# Create a rich table for years summary
years_table = Table(title="IRS Form 990 Repository - Years Summary")
years_table.add_column("Year", style="cyan")
years_table.add_column("Index Files", style="green")
years_table.add_column("CSV Files", style="yellow")
years_table.add_column("ZIP Files", style="magenta")
years = sorted(repository_map["years"].keys())
for year in years:
index_files = repository_map["years"][year]["index_files"]
csv_count = sum(1 for f in index_files if f["file_type"] == "csv")
zip_count = sum(1 for f in index_files if f["file_type"] == "zip")
years_table.add_row(
year,
str(len(index_files)),
str(csv_count),
str(zip_count)
)
console.print(years_table)
# Create a table for index file structures
if sampled_indexes:
structure_table = Table(title="Sample Index File Structures")
structure_table.add_column("Year", style="cyan")
structure_table.add_column("File", style="green")
structure_table.add_column("Type", style="yellow")
structure_table.add_column("Columns", style="magenta")
structure_table.add_column("EIN Column", style="blue")
for sample in sampled_indexes:
if sample.get("structure_analyzed", False) and sample.get("file_type") == "csv":
structure_table.add_row(
sample.get("year", ""),
sample.get("url", "").split('/')[-1],
sample.get("file_type", "").upper(),
str(len(sample.get("column_headers", []))),
sample.get("ein_column_name", "Not found")
)
console.print(structure_table)
# Create a summary report file
report_path = MAPPER_DIR / "repository_summary.txt"
with open(report_path, "w") as f:
f.write("IRS FORM 990 REPOSITORY STRUCTURE SUMMARY\n")
f.write("=========================================\n\n")
f.write(f"Total Years: {len(years)}\n")
f.write(f"Total Index Files: {repository_map['index_files_count']}\n\n")
f.write("Years Available:\n")
for year in years:
index_files = repository_map["years"][year]["index_files"]
csv_count = sum(1 for f in index_files if f["file_type"] == "csv")
zip_count = sum(1 for f in index_files if f["file_type"] == "zip")
f.write(f" {year}: {len(index_files)} index files ({csv_count} CSV, {zip_count} ZIP)\n")
f.write("\nIndex File Structures:\n")
for sample in sampled_indexes:
if sample.get("structure_analyzed", False):
f.write(f" {sample.get('year', '')} - {sample.get('url', '').split('/')[-1]}:\n")
if sample.get("file_type") == "csv":
headers = sample.get("column_headers", [])
f.write(f" Type: CSV\n")
f.write(f" Columns: {len(headers)}\n")
f.write(f" Headers: {', '.join(headers)}\n")
f.write(f" EIN Column: {sample.get('ein_column_name', 'Not found')}\n")
f.write(f" Object ID Column: {sample.get('object_id_column_name', 'Not found')}\n")
else:
f.write(f" Type: ZIP\n")
f.write(f" File Size: {sample.get('file_size', 'Unknown')} bytes\n")
f.write(f" Note: {sample.get('note', '')}\n")
f.write("\n")
console.print(f"[green]Summary report saved to [italic]{report_path}[/italic][/green]")
def main():
"""Main function to map the IRS Form 990 repository structure."""
console.print("[bold green]IRS Form 990 Repository Structure Mapper[/bold green]")
console.print("This script maps the structure of the IRS Form 990 data repository without downloading actual filings.\n")
# Step 1: Analyze the downloads page
repository_map = explore_downloads_page()
if repository_map:
# Step 2: Sample a few index files to understand their structure
console.print("\n[bold blue]Sampling index files to understand their structure...[/bold blue]")
sampled_indexes = []
# Sample one CSV index file from each year (if available)
with Progress() as progress:
years = sorted(repository_map["years"].keys(), reverse=True)
task = progress.add_task("[cyan]Sampling index files...", total=len(years))
for year in years:
index_files = repository_map["years"][year]["index_files"]
# Try to find a CSV file first
csv_files = [f for f in index_files if f["file_type"] == "csv"]
if csv_files:
file_info = csv_files[0]
console.print(f"Sampling CSV index file for year [bold]{year}[/bold]: {file_info['url'].split('/')[-1]}")
sample = sample_index_file_structure(file_info["url"], file_info["file_type"], year)
sampled_indexes.append(sample)
# Also sample one ZIP file if available
zip_files = [f for f in index_files if f["file_type"] == "zip"]
if zip_files:
file_info = zip_files[0]
console.print(f"Sampling ZIP index file for year [bold]{year}[/bold]: {file_info['url'].split('/')[-1]}")
sample = sample_index_file_structure(file_info["url"], file_info["file_type"], year)
sampled_indexes.append(sample)
progress.update(task, advance=1)
# Step 3: Generate visualizations
generate_repository_visualization(repository_map)
# Step 4: Generate summary report
generate_summary_report(repository_map, sampled_indexes)
console.print("\n[bold green]Repository mapping complete![/bold green]")
console.print(f"All mapping information has been saved to the [italic]{MAPPER_DIR}[/italic] directory.")
console.print("Review the following files:")
console.print(f" - [bold]Repository Map:[/bold] {MAPPER_DIR}/repository_map.json")
console.print(f" - [bold]Index Structures:[/bold] {INDEX_INFO_DIR}/")
console.print(f" - [bold]Visualizations:[/bold] {VISUALIZATION_DIR}/")
console.print(f" - [bold]Summary Report:[/bold] {MAPPER_DIR}/repository_summary.txt")
else:
console.print("[bold red]Failed to map repository structure. Check logs for details.[/bold red]")
if __name__ == "__main__":
main()Results
Table 1. Nonprofit Financial Metrics - Repository Structure by Year.
| Year | Index Files | CSV Files | ZIP Files |
|---|---|---|---|
| 2019 | 10 | 1 | 9 |
| 2020 | 10 | 1 | 9 |
| 2021 | 2 | 1 | 1 |
| 2022 | 2 | 1 | 1 |
| 2023 | 13 | 1 | 12 |
| 2024 | 13 | 1 | 12 |
| 2025 | 3 | 1 | 2 |
Table 2. Sample Index File Structures Across Years.
| Year | File | Type | Columns | EIN Column |
|---|---|---|---|---|
| 2025 | index_2025.csv | CSV | 10 | EIN |
| 2024 | index_2024.csv | CSV | 10 | EIN |
| 2023 | index_2023.csv | CSV | 9 | EIN |
| 2022 | index_2022.csv | CSV | 9 | EIN |
| 2021 | index_2021.csv | CSV | 9 | EIN |
| 2020 | index_2020.csv | CSV | 9 | EIN |
| 2019 | index_2019.csv | CSV | 9 | EIN |
Output files generated:
- Repository map: irs_mapping/repository_map.json
- Index file structure information: irs_mapping/index_info/
- Visualizations: irs_mapping/visualizations/
- Summary report: irs_mapping/repository_summary.txt
Discussion
The computational mapping of the IRS Form 990 repository revealed a systematic organization of nonprofit financial data that follows a consistent hierarchical structure across years, with important variations in file distribution and availability. The script identified 53 distinct index files across 7 years (2019-2025), with a consistent pattern of organization. The repository demonstrates a two-tier index system with primary CSV indices and supplementary ZIP archives that together provide access pathways to the underlying XML filings.
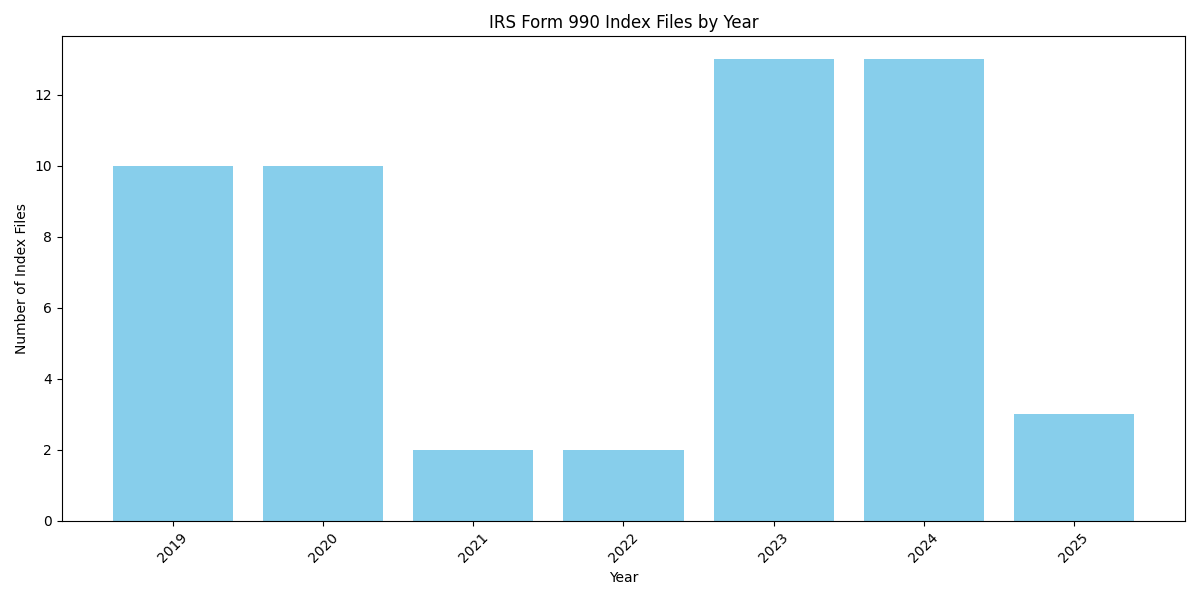
As shown in Table 1, the availability of index files varies significantly across years, with 2023 and 2024 having the most extensive coverage (13 files each), while 2021 and 2022 have minimal coverage (2 files each). This variation suggests potential changes in the IRS’s data publication practices or could reflect the ongoing population of newer years’ repositories. The pattern visible in Figure 1 particularly highlights this inconsistency, with the middle years (2021-2022) showing significantly fewer index files compared to both older and newer years.
Each year in the repository consistently includes a single CSV index file and multiple ZIP archives, although the number of ZIP files varies by year. As demonstrated in Table 2, the CSV index files maintain a relatively consistent structure across years, with all files containing an explicit “EIN” column that allows for targeted organization lookup. The column count shows minor variations, with 2019-2023 containing 9 columns while 2024-2025 contain 10 columns, potentially indicating a recent enhancement to the index information provided.
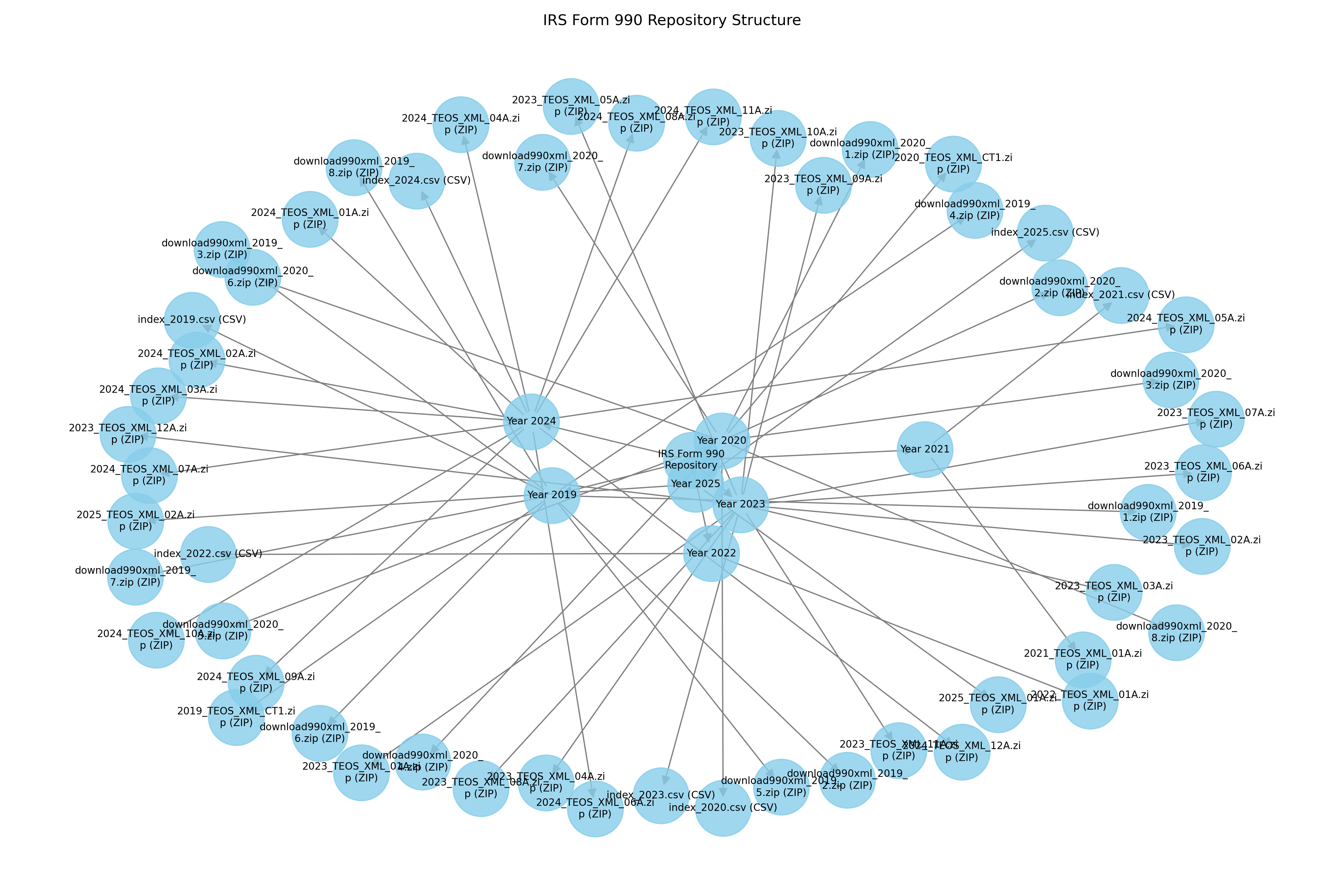
The network visualization in Figure 2 illustrates the complex interconnections in the repository structure, highlighting the central organization by year with radiating connections to individual index files. This visualization emphasizes the two-tier structure, with each year node connecting to both a CSV index and multiple ZIP archives, providing a clear mental model for developing targeted retrieval strategies.
The consistent presence of an EIN column in all CSV index files is particularly significant for our research objectives, as it provides a direct lookup mechanism for locating specific nonprofit organizations within the repository. This confirms the feasibility of targeted retrieval strategies that first query the CSV indices to locate specific organizations before accessing the relevant XML filings, potentially from within the associated ZIP archives.4
Our previous attempts at direct XML retrieval using constructed URLs encountered consistent 404 errors, suggesting that the XML files might not be directly accessible at the expected paths. This finding, combined with the repository structure mapping, indicates that the actual XML filings are likely contained within the ZIP archives rather than exposed as individual files. This architectural pattern is logical from a server management perspective, as it reduces the number of individual files that must be hosted while still providing organized access through the index system.
The mapping results provide critical insights for developing a more effective retrieval approach. Rather than attempting to directly access XML files through constructed URLs (which consistently failed with 404 errors), a more effective strategy emerges from our analysis. This approach begins with downloading and parsing the appropriate year’s CSV index file, followed by filtering the index to identify entries matching target EINs. The next phase involves determining which ZIP archives contain the relevant filings, enabling selective downloading of only these necessary archives. The final step extracts the specific XML filings for the target organizations from these archives, completing a targeted retrieval process that minimizes unnecessary data transfer while ensuring comprehensive coverage of desired records.4
This targeted approach would significantly reduce unnecessary data transfer and processing compared to downloading all available files, making it feasible to retrieve comprehensive data for specific organizations across multiple years. Moreover, the consistent structure of the index files facilitates automation of this process, enabling programmatic access to the repository at scale.5
The repository’s organization by year also provides opportunities for longitudinal analyses, as the consistent structure makes it feasible to retrieve data for the same organizations across multiple years. However, the variation in file availability across years (as shown in Table 1 and Figure 1) suggests potential gaps in data coverage that should be considered when designing research methodologies dependent on this data source.
Conclusion
This study has successfully mapped the structure of the IRS Form 990 data repository, revealing a consistent hierarchical organization with year-based grouping, a two-tier index system of CSV and ZIP files, and a standardized approach to referencing individual filings. The mapping identified 53 distinct index files across 7 years (2019-2025), with variations in distribution that provide insights into the repository’s evolution.
The repository demonstrates a systematic organization with primary CSV index files containing EIN references that can be used for targeted lookup of nonprofit organizations. These indices are supplemented by ZIP archives that likely contain the actual XML filings, creating a space-efficient storage system that still enables targeted retrieval when properly navigated.
Understanding this repository structure is a crucial first step in developing efficient methods for accessing Form 990 data programmatically. The findings suggest that a targeted approach utilizing the CSV indices for initial lookup, followed by selective downloading and extraction from the appropriate ZIP archives, would provide the most efficient path to retrieving specific organizational filings.5
Future work should focus on implementing and testing this targeted retrieval approach, including verification of the ZIP file contents and development of optimized extraction methods. Additionally, exploration of the XML file structures would be valuable for developing efficient parsing strategies to extract specific financial metrics like Program Efficiency (PE) and Fundraising Efficiency (FE) from the retrieved filings.6
This mapping provides a foundation for more effective access to primary source Form 990 data, potentially enabling more comprehensive and reliable analyses of nonprofit financial metrics than previously possible through third-party APIs with their inherent limitations in coverage and field availability.2 As highlighted by Williams and Akaakar, the delays and barriers to accessing IRS Form 990 data represent “real risks for nonprofits,” making improvements in data accessibility crucial for sector-wide transparency and efficacy.1